介绍
LSM-Tree全称Log Structured Merge Tree,是一种分层、有序、面向磁盘的数据结构,其核心思想是充分利用磁盘的顺序写性能要远高于随机写性能这一特性,将批量的随机写转换为一次性的顺序写。
LSM-Tree的写入操作,类似于普通的日志写入方式,以Append的模式追加;删除操作Append一条删除的日志;修改操作Append一条新key-value。
LSM-Tree很适合用于key-value数据的高效索引和持久化存储。一些广泛使用的存储系统BigTable、LevelDB、RocksDB(可以充当MySQL的存储引擎)都用到了这项技术。
MySQL的InnoDB存储引擎使用了B+树(拥有平衡的读写性能),单次写入需要改变多个节点,这些节点存在硬盘中不同的位置,可能需要进行多次硬盘随机写入,一般来说,硬盘的顺序写入速度远快于随机写入
LSM-Tree非就地更新
数据的更新策略:
- 就地更新:直接覆盖旧记录以存储更新,比如B+Tree,通常读多写少;
- 非就地更新:将更新动作写入一条新的记录,而不是覆盖旧条目,比如LSM-Tree,通常写多读少;
- 利用顺序I/O处理写操作,写性能较高;
- 查找操作需要顺序按层遍历,读性能较弱;
LSM-Tree组成部分
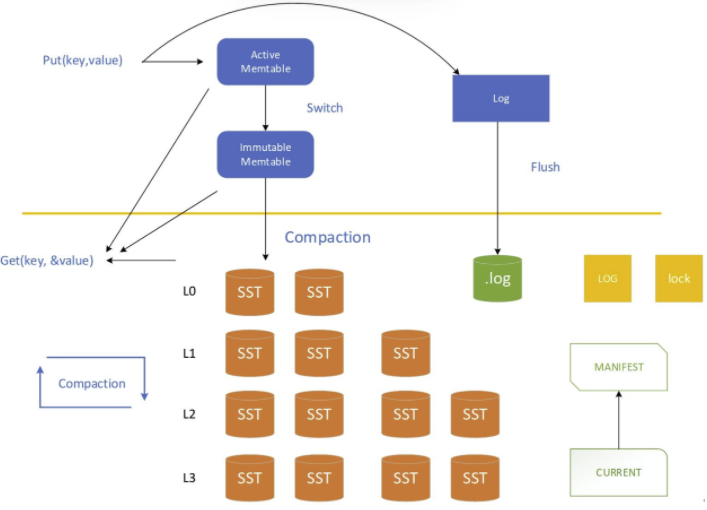
LSM-Tree有内存组件和硬盘组件两部分。
内存组件:包含Memtable和Immutable MemTable,通常使用skip-list或B+树结构
- Memtable:数据直接写入MemTable;
- Immutable MemTable: 不可写,被冻结的MemTable,等待被合并到硬盘;
硬盘组件:包含不同Level的SSTable(sorted string table),每个组件都是单独的B树(append-only B-tree)
- Level越低,数据越新,容量越少;反之Level越高,数据越旧,容量越大;
- 低Level的SSTable被合并到高Level的SSTable,合并过程中会做删除操作(相同key删除旧值保留新值);
- SSTable中除了数据块,还含有索引块,便于块内数据的快速查找;
MemTable
MemTable提供了k-v数据的写入、读取和删除接口。
按key顺序存储,以便被合并到SSTable后仍然有序。
Immutable MemTable
由于内存有限,当MemTable达到一定阈值后,将其冻结成Immutable MemTable,并生成新的MemTable。
Immutable MemTable的内容达到一定阈值后,将其合并到SSTable。
使用Immutable MemTable的原因:若直接使用MemTable,MemTable被合并到SSTable过程中,会阻塞用户的写操作。
WAL
WAL(Write-Ahead-Log)预写日志,用于保证宕机时数据不丢失。
写入数据时,同时写入MemTable和WAL;由于WAL是顺序写,速度很快。
当程序宕机时,可以从WAL恢复数据到MemTable。
SSTable
SSTable(sorted string table)是Immutable MemTable在磁盘上的存储,内部按key顺序排列。
为了加快SSTable的查询速度,在SSTable中增加索引信息,可以快速定位key并查到其value。
SSTable是分层结构,Immutable Memtable达到阈值后被合并进L0的SSTable,L0的SSTable达到阈值后,会和L1的SSTable合并;由于SSTable是有序时,SSTable的合并相当于归并操作,速度很快。
SSTable合并策略
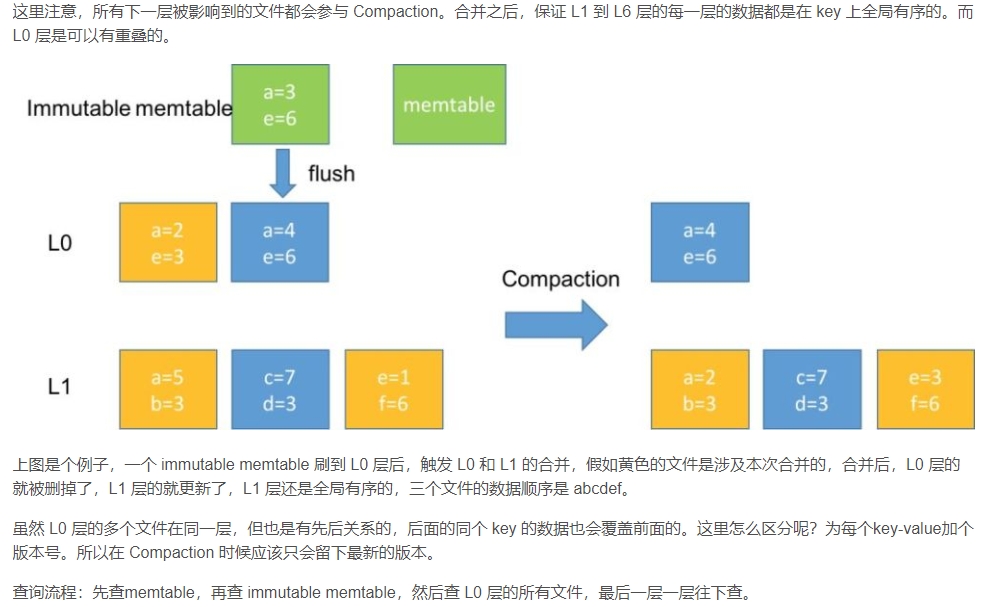
磁盘中低Level的SSTable被合并到高Level中,合并过程中,可以做删除操作,降低磁盘使用,比如L0中foo=b,L1中foo=a,由于L0是更新的数据,故合并后foo=b,同时删掉L1中foo=a的记录。
SSTable有两种合并策略:
- Leveling Merge Policy:
每个level仅有1个组件,L0和L1合并,合并到L1中;
由于组件较少,查询性能较高,LevelDB和RocksDB使用该策略;
- Tiering Merge Policy:
每个Level有N个组件,合并后生成Level+1的一个新组件;
由于可以降低合并的频率,写入性能较高;
LSM-Tree插入更新删除
- 第一步,键值对首先以追加方式写入log文件中。这是持久化最重要的一步,保证服务器崩溃时数据不丢失,同时顺序写入也保证了写入性能非常好。
- 第二步,键值对会被追加到的Memtable,由于在内存之中,这个过程非常快。对于用户来讲,写入操作就结束了。接下来的步骤是后台线程异步执行的。
- 第三步,当Memtable的大小达到阈值时,磁盘中低Level的SSTable被合并到高Level中,这个操作被称为compaction。两者合并生成的新文件会被顺序写入硬盘,取代旧版本。
- 第四步,compaction操作同样发生在L0到Lk组件中。当任意Li的大小达到阈值,都将触发compaction,与下层Li+1合并。
- 对于更新操作,更新数据==写入一个新的k-v数据。整个LSM-Tree中可能存在多个key相同的数据,在合并SSTable的时候,会将旧值删除
- 删除操作仅记录key的删除操作标记,并不立即从文件中删除;当合并SSTable时,才真正的将数据删除。
LSM-Tree中读取数据
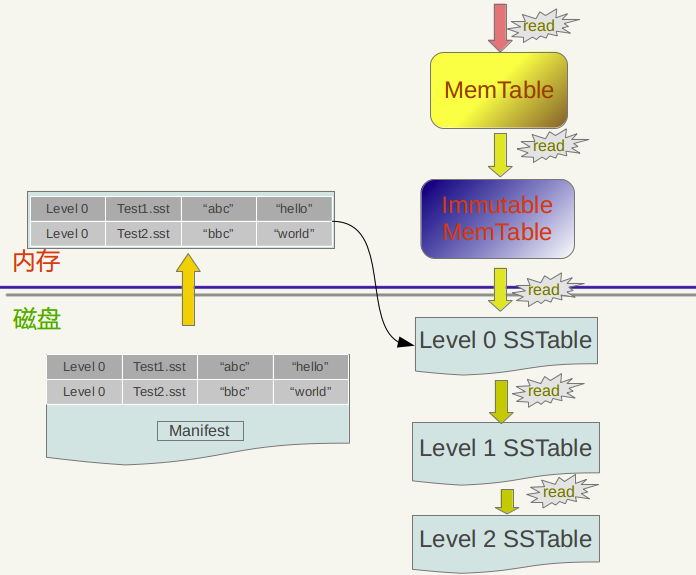
LSM-Tree的读取效率并不高,查找过程:
- 先查找内存Memtable和Immutable,找到即返回
- 然后分别查找磁盘L0 SSTable->L1 SSTable->…,找到即返回
- 对于查询不存在的数据,LSM-trees需要查遍所有组件。因此,一般来说,对于查询操作,LSM-trees相对于B-tree耗时更大
LSM-Tree读取的优化
LevelDB Manifest文件
manifest文件记录所有的SSTable信息,比如Level、最小key、最大key等,可以用于快读定位目标SSTable。这样在查找时,先将SSTable的manifest读到内存中再进行判断,不用整个SSTable读入。SSTable的索引块
每个SSTable文件中加入索引块,索引块中记录key及其offset,key按顺序排列。这样在查找时,先在索引中二分查找key和offset,然后再到SSTable中读取key-value。SSTable的布隆过滤器
对SSTable指定布隆过滤器,判定一个SSTable是否包含特定的建,以减少访问磁盘次数。这样在查找时,根据BloomFilter可以快速确定某个key是否在当前SSTable中。