异步消息队列
Redis 的 list(列表) 数据结构常用来作为异步消息队列使用,使用rpush/lpush操作入队列,使用lpop 和 rpop来出队列。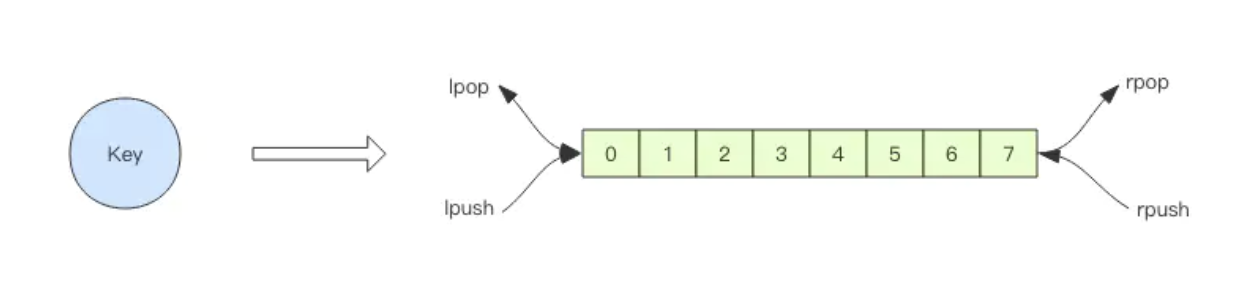
客户端是通过队列的 pop 操作来获取消息,然后进行处理。处理完了再接着获取消息,再进行处理。如此循环往复(while),这便是作为队列消费者的客户端的生命周期。
如果队列空了,客户端就会陷入 pop 的死循环,不停地 pop,没有数据,接着再 pop,又没有数据。这就是浪费生命的空轮询。空轮询不但拉高了客户端的 CPU,redis 的 QPS 也会被拉高。
解决方法:用blpop/brpop替代前面的lpop/rpop. 阻塞读在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则立刻醒过来。消息的延迟几乎为零
如果线程一直阻塞在哪里,Redis 的客户端连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用。这个时候blpop/brpop会抛出异常来。所以编写客户端消费者的时候要小心,注意捕获异常,还要重试。
延时队列
做电商项目的时候会遇到如下场景
- 订单下单后超过一小时用户未支付,需要关闭订单
- 订单的评论如果7天未评价,系统需要自动产生一条评论
这个时候就用到延时队列了,顾名思义就是需要延迟一段时间后执行。可以通过 Redis 的 zset(有序列表) 来实现。我们将消息序列化成一个字符串作为 zset 的value,这个消息的到期处理时间作为score,然后用多个线程轮询 zset 获取到期的任务进行处理,
多个线程是为了保障可用性,万一挂了一个线程还有其它线程可以继续处理。因为有多个线程,所以需要考虑并发争抢任务,确保任务不能被多次执行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29//添加任务
public void delay(T msg) {
TaskItem<T> task = new TaskItem<T>();
task.id = UUID.randomUUID().toString(); // 分配唯一的 uuid
task.msg = msg;
String s = JSON.toJSONString(task); // fastjson 序列化
jedis.zadd(queueKey, System.currentTimeMillis() + 5000, s); // 塞入延时队列 ,5s 后再试
}
//拉任务
public void loop() {
while (!Thread.interrupted()) {
// 只取一条
Set<String> values = jedis.zrangeByScore(queueKey, 0, System.currentTimeMillis(), 0, 1);
if (values.isEmpty()) {
try {
Thread.sleep(500); // 歇会继续
} catch (InterruptedException e) {
break;
}
continue;
}
String s = values.iterator().next();
if (jedis.zrem(queueKey, s) > 0) { // 抢到了
TaskItem<T> task = JSON.parseObject(s, TaskType); // fastjson 反序列化
this.handleMsg(task.msg); //业务处理
}
}
}
Redis 的 zrem 方法是多线程多进程争抢任务的关键,它的返回值决定了当前实例有没有抢到任务, 因为 loop 方法可能会被多个线程、多个进程调用,同一个任务可能会被多个进程线程抢到,通过 zrem 来决定唯一的属主。还可以优化为将 zrangebyscore和zrem使用lua脚本进行原子化操作。
位图
位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是 byte 数组。我们可以使用普通的 get/set 直接获取和设置整个位图的内容,也可以使用位图操作 getbit/setbit 等将 byte 数组看成「位数组」来处理。
优点: 通过一个bit位来表示某个元素对应的值或者状态,8个bit可以组成一个Byte,及其节省空间。setbit和getbit的时间复杂度都是O(1),其他位运算效率也高
缺点: 本质上位只有0和1的区别,所以用位做业务数据记录,就不需要在意value的值。
使用场景:可以计算用户日活、月活、留存率的统计;可以统计用户在线状态和人数; 用户签到等
具体实施(日活 月活):使用redis的位图bitmap
- 设置一个key专门用来记录用户日活的,比如1号的key为active01.
- 使用每个用户的唯一标识映射一个偏移量,比如使用user_id,这里可以把user_id换算成一个数字作为该用户在当天是否活跃偏移量(每个用户对应一个bit)
- 用户登录则把该用户偏移量上的位值设置为1
- 每天按日期生成一个位图(bitmap)
- 计算日活则使用bitcount即可获得一个key的位值为1的量
- 计算月活(一个月内登陆的用户去重总数)即可把30天的所有bitmap做or计算,然后再计算bitcount
HyperLogLog
如果要统计网站的PV(Page View),你可以使用Redis计数器就好了,每来一个请求,调用一次incrby即可。
但是如果要统计UV(Unique Visitor)就没那么简单呢,它需要去重,当然你肯定想到了Redis中的去重的Set集合,当一个请求过来使用sadd添加用户ID,通过scard取出集合的大小。但是如果上千万的UV,使用集合来统计,就非常浪费空间了。
而Redis提供的HyperLogLog数据结构正是来解决这类统计问题的,当然在数据量很大的情况下,他会有一定的误差。HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,标准误差是 0.81%
使用方法:
HyperLogLog 提供了两个指令 pfadd 和 pfcount,根据字面意义很好理解,一个是增加计数,一个是获取计数。pfadd 用法和 set 集合的 sadd 是一样的,来一个用户 ID,就将用户 ID 塞进去就是。pfcount 和 scard 用法是一样的,直接获取计数值。1
2
3
4
5
6
7
8
9
10
11
12127.0.0.1:6379> pfadd uv_p1 user1
(integer) 1
127.0.0.1:6379> pfcount uv_p1
(integer) 1
127.0.0.1:6379> pfadd uv_p1 user2
(integer) 1
127.0.0.1:6379> pfcount uv_p1
(integer) 2
127.0.0.1:6379> pfadd uv_p1 user2
(integer) 0
127.0.0.1:6379> pfcount uv_p1
(integer) 2
HyperLogLog还提供了第三个指令 pfmerge,用于将多个 pf 计数值累加在一起形成一个新的 pf 值。
比如在网站中我们有两个内容差不多的页面,运营需要将两个页面的数据进行合并。其中页面的 UV 访问量也需要合并,这时候就可以使用pfmerge。
如果用户id是连续的,也可以用bitmap来统计UV,时间+网页标示作为key,用户id为偏移量. 以前用过bitmap来做,setbit uv:day userid 1,空间占用大 利用率不高
布隆过滤器
Redis 官方提供的布隆过滤器到了 Redis 4.0 提供了插件功能之后才正式登场。布隆过滤器作为一个插件加载到 Redis Server 中,给 Redis 提供了强大的布隆去重功能。
当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。 布隆过滤器的原理就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。
布隆过滤器,作用和set类似(去重集合),优势是:极大的节省存储空间,不足是:稍微有些不准确,有误差;它的核心竞争力和HyperLogLog类似,节省存储空间
主要命令有:
- bf.add 添加元素
- bf.exists 查询元素是否存在
- bf.madd 一次添加多个元素
- bf.mexists 一次查询多个元素是否存在
在 redis 中有两个值决定布隆过滤器的准确率:
- error_rate:允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大。
- initial_size:布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
一个命令可以来设置这两个值:
bf.reserve test 0.01 100 必须在add之前使用bf.reserve指令显式创建,如果对应的 key 已经存在,bf.reserve会报错。默认的error_rate是 0.01,默认的initial_size是 100。
应用场景: 主要是解决大规模数据下不需要精确过滤的场景,如检查垃圾邮件地址,爬虫URL地址去重,解决缓存穿透问题等。
简单限流
所谓的滑动时间算法指的是以当前时间为截止时间,往前取一定的时间,比如往前取 60s 的时间,如果要求每60s之内运行最大的访问数为100,此时算法的执行逻辑为,先清除 60s 之前的所有请求记录,再计算当前集合内请求数量是否大于设定的最大请求数 100,如果大于则执行限流拒绝策略,否则插入本次请求记录并返回可以正常执行的标识给客户端。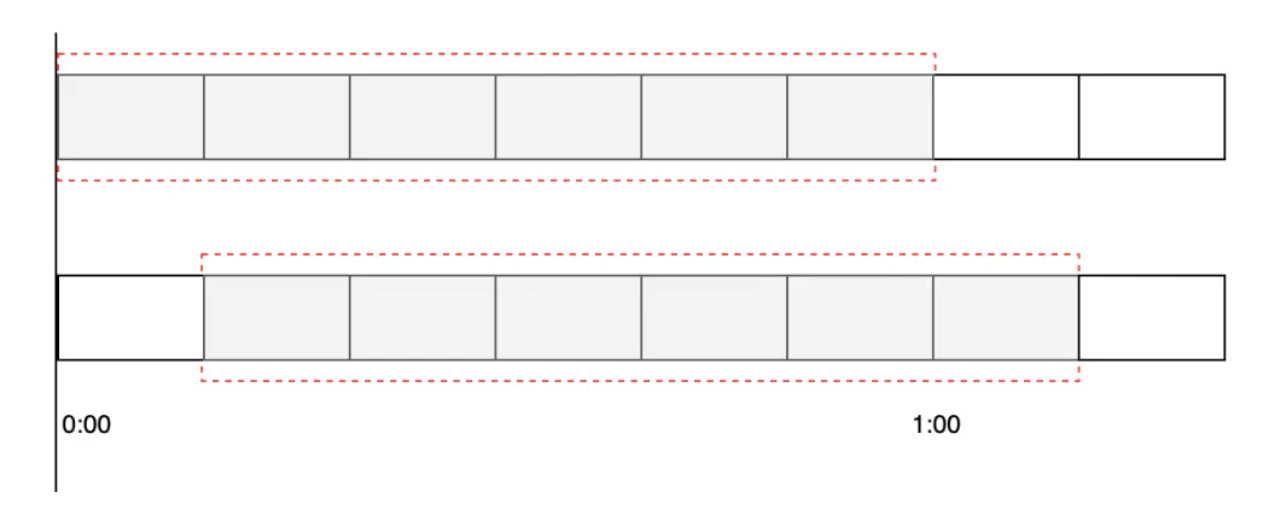
借助 Redis 的有序集合 ZSet 来实现时间窗口算法限流,实现的过程是先使用 ZSet 的 key 存储限流的 ID(通常是用户ID+行为ID),score 用来存储请求的时间,每次有请求访问来了之后,先清空之前时间窗口的访问量,统计现在时间窗口的个数和最大允许访问量对比,如果大于等于最大访问量则返回 false 执行限流操作,否则允许执行业务逻辑,并且在 ZSet 中添加一条有效的访问记录,代码如下。
1 | /** |
整体思路就是:每一个行为到来时,都维护一次时间窗口。将时间窗口外的记录全部清理掉,只保留窗口内的记录。zset 集合中只有 score 值非常重要,value 值没有特别的意义,只需要保证它是唯一的就可以了。在这就用时间戳即可
滑动时间窗口的限流策略:比起incrby+过期时间计数器限流(在窗口边界可能有波动)而言 这样控制流量会更平滑