前言
最开始在爬虫的时候因为URL去重了解到了布隆过滤器,而缓存穿透问题又使用到了布隆过滤。因此我又去加深理解了一番,这真是一个有趣的算法,故在此记下笔记以便以后复习总结。
基本思想
如果我们想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,需要的内存空间越来越大,检索速度也越来越慢。这种方法就不适用了,
但是有一种叫作哈希表的数据结构,它占用很小的内存空间而且有着高效的查询效率=》通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了
介绍
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。—-百度百科
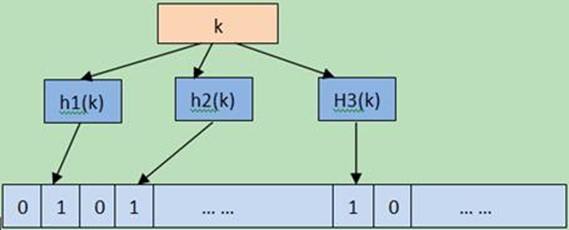
一个空的布隆过滤器是由m个bits组成的bit array,每一个bit位都初始为0。并且定义有k个不同的哈希函数,每个哈希函数都将元素哈希到bit array的不同位置。
当添加一个元素时,用k个哈希函数分别将它hash得到k个bit位,然后将这些bit位置位1。
查询一个元素时,同样用k个哈希函数将它hash,再判断k个bit位上是否都为1,如果都是1那么可能存在于集合中;如果其中某一位为0,则该元素肯定不存在于布隆过滤器中。
- 为什么说可能不存在:这一点和 HashMap 类似,在有限的数组长度中存放大量的数据,即便是再完美的 Hash 算法也会有冲突,所以有可能两个完全不同的 A、B 两个元素最后定位到的位置是一模一样的。因此后来的元素B可能误报存在。
- 同理不能删除元素,因为B删除了会影响原先已存在的元素A误报不存在。
在Hash冲突的前提,所以Bloom Filter存在一定的误报率,这个误报率和Hash算法的次数,以及位数组长度都是有关的。
Google Guava实现
Guava是Google推出的一种基于Java的开源核心库,这个库提供用于集合,缓存,并发等,其中也实现了布隆过滤。
public static void main(String[] args) {
long star = System.currentTimeMillis();
int size = 1000000;
BloomFilter bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
int num = 0, total = 100000;
for (int i = size; i < size + total; i++) {
if (bloomFilter.mightContain(i)) {
num++;
}
}
System.out.println(total +"条不存在的数据被误判存在的数量为" + num);
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - star));
}
100000条不存在的数据被误判存在的数量为3033
执行时间:729
可以看出谷歌的方法默认误判率是3%, Guava 会通过你预计的数量以及误报率帮你计算出你应当会使用的数组大小以及需要计算几次 Hash函数。