介绍
函数和其他类型一样都属于“一等公民”,其他类型能够实现接口,函数也可以。这种在调用的时候就会非常简便,这种函数,称为接口型函数,这种方式使用于只有一个函数的接口。
这样,既能够将普通的函数类型(需类型转换)作为参数,也可以将结构体作为参数,使用更为灵活,可读性也更好,这就是接口型函数的价值。
函数和其他类型一样都属于“一等公民”,其他类型能够实现接口,函数也可以。这种在调用的时候就会非常简便,这种函数,称为接口型函数,这种方式使用于只有一个函数的接口。
这样,既能够将普通的函数类型(需类型转换)作为参数,也可以将结构体作为参数,使用更为灵活,可读性也更好,这就是接口型函数的价值。
LSM-Tree全称Log Structured Merge Tree,是一种分层、有序、面向磁盘的数据结构,其核心思想是充分利用磁盘的顺序写性能要远高于随机写性能这一特性,将批量的随机写转换为一次性的顺序写。
LSM-Tree的写入操作,类似于普通的日志写入方式,以Append的模式追加;删除操作Append一条删除的日志;修改操作Append一条新key-value。
LSM-Tree很适合用于key-value数据的高效索引和持久化存储。一些广泛使用的存储系统BigTable、LevelDB、RocksDB(可以充当MySQL的存储引擎)都用到了这项技术。
MySQL的InnoDB存储引擎使用了B+树(拥有平衡的读写性能),单次写入需要改变多个节点,这些节点存在硬盘中不同的位置,可能需要进行多次硬盘随机写入,一般来说,硬盘的顺序写入速度远快于随机写入
mysql 使用了 WAL 技术,即更新的时候先更新内存中的数据,然后必要的时候再将内存中的数据刷入磁盘。我们把内存中这些被修改过,跟磁盘中的数据页不一致的数据页称为”脏页”. 内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”
平时执行很快的更新操作,其实就是在写内存和日志,而MySQL偶尔“抖”一下的那个瞬间,可能就是在刷脏页(flush)
其中,有四种情况会触发脏页的刷盘:
从这里就可以看出: 数据flush 同步是通过刷新内存page 完成的 不是通过redo log
若是每一次的更新操作(例如insert、update和delete操做)都要操作磁盘,IO成本实在过高。 InnoDB 的数据是按数据页为单位来读写的。当须要读一条记录的时候,并非将这个记录自己从磁盘读出来,而是以页为单位(16KB),将其总体读入内存
当须要更新一个记录,就是要更新一个数据页:
将 change buffer 中的操作应用到原数据页,获得最新结果的过程称为 merge,更新操作避免了大量的磁盘随机访问I/O。
merge之后这时候Page为脏页了,不用担心,InnoDB会在合适的时候flush进行数据落地
redo log又叫重做日志,提供的是数据丢失后的前滚操作。
redo log是innodb引擎独有的日志,使用了 WAL 技术(Write-Ahead Logging),也就是预写日志。它的关键点就是先写日志,再写磁盘。对应到Mysql中具体操作,就是每次更新操作,先写日志,然后更新内存数据,最后等系统压力小的时候再进行IO更新磁盘数据。避免了每一次更新都需要进行IO操作。redo log 是保证了事务持久性的关键。
redo log 一般用在数据库恢复的情况:
如果是正常运行的实例的话,数据页被修改以后,跟磁盘的数据页不一致,称为脏页。最终数据落盘,就是把内存中的数据页写盘。这个过程,与 redo log 毫无关系。InnoDB会在后台刷脏页,而刷脏页的过程是要将内存页写入磁盘
正常运行中的实例,数据写入后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的呢?
实际上,redo log并没有记录数据页的完整数据,所以它并没有能力自己去更新磁盘数据页,也就不存在“数据最终落盘,是由redo log更新过去”的情况。
在崩溃恢复场景中,InnoDB如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它读到内存,然后让redo log更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态。
另外,redo log与undo log都被叫做事务日志。
Redis 的 list(列表) 数据结构常用来作为异步消息队列使用,使用rpush/lpush操作入队列,使用lpop 和 rpop来出队列。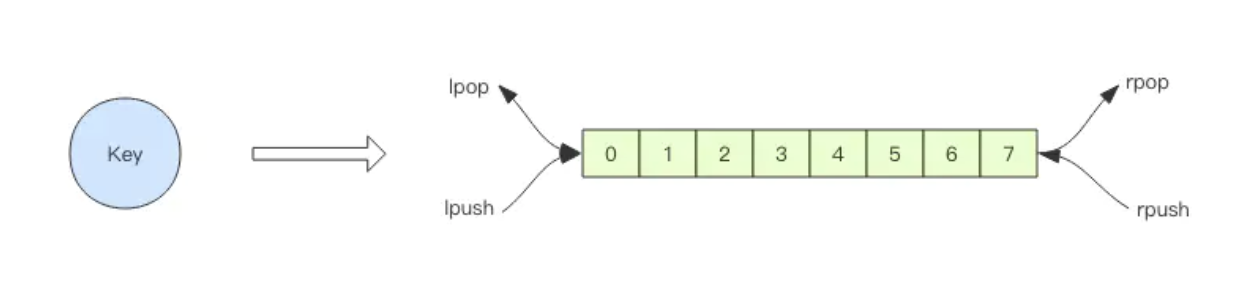
客户端是通过队列的 pop 操作来获取消息,然后进行处理。处理完了再接着获取消息,再进行处理。如此循环往复(while),这便是作为队列消费者的客户端的生命周期。
如果队列空了,客户端就会陷入 pop 的死循环,不停地 pop,没有数据,接着再 pop,又没有数据。这就是浪费生命的空轮询。空轮询不但拉高了客户端的 CPU,redis 的 QPS 也会被拉高。
解决方法:用blpop/brpop替代前面的lpop/rpop. 阻塞读在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则立刻醒过来。消息的延迟几乎为零
TCP要保证所有的数据包都可以到达,所以必需要有重传机制。
接收端给发送端的Ack确认只会确认最后一个连续的包,比如发送端发了1,2,3,4,5一共五份数据,接收端收到了1,2,于是会ack 3,然后收到了4,5(注意此时3因为可能丢包没收到),还是只会ack 3.
直观的解决方法是:接收方不做任何处理,当发送方发现收不到3的ack超时后,然后重传。缺点在于发送端不知道该重发3,还是重发3,4,5。这种就是被动等待的超时重传策略
永远记住 ACK 确认号是表示这之前的包都已经全部收到
TCP 是一个可靠的(reliable)、面向连接的(connection-oriented)、基于字节流(byte-stream)、全双工(full-duplex)的协议。发送端在发送数据以后启动一个定时器,如果超时没有收到对端确认会进行重传,接收端利用序列号对收到的包进行排序、丢弃重复数据,TCP 还提供了流量控制、拥塞控制等机制保证了稳定性。
动态规划(Dynamic programming,简称 DP)常常适用于有重叠子问题和最优子结构性质的问题.
递归树中重复计算产生了重叠子问题而引入了备忘录,动态规划最优子结构是通过求子问题的最优解,可以得到原问题的最优解(一般求max min等)
动态规划背后的基本思想非常简单。大致上,若要解一个给定问题,我们需要解其不同部分(即子问题),再根据子问题的解以得出原问题的解。动态规划往往用于优化递归问题,例如斐波那契数列,如果运用递归的方式来求解会重复计算很多相同的子问题,利用动态规划的思想可以减少计算量
核心思想是把一个复杂的大问题拆成若干个子问题,通过解决子问题来逐步解决大问题
动态规划其实和分治策略是类似的,也是将一个原问题分解为若干个规模较小的子问题,递归的求解这些子问题,然后合并子问题的解得到原问题的解。区别在于这些子问题会有重叠,一个子问题在求解后,可能会再次求解,于是我们想到将这些子问题的解存储起来,当下次再次求解这个子问题时,直接拿过来就是
分治策略一般用于解决子问题相互独立的情况,一般用递归实现;而动态规划则用于解决子问题有重叠的情况,既可以用递归备忘录实现,也可以用动态规划迭代实现
红黑树本质上是一种二叉查找树,但它在二叉查找树的基础上额外添加了一个标记(颜色),同时具有一定的规则。这些规则使红黑树保证了一种平衡,插入、删除、查找的最坏时间复杂度都为 O(logn)。
它的综合性能要好于平衡二叉树(AVL树),因此,红黑树在很多地方都有应用。比如在 Java 集合框架中,很多部分(HashMap, TreeMap, TreeSet 等)都有红黑树的应用,这些集合均提供了很好的性能。
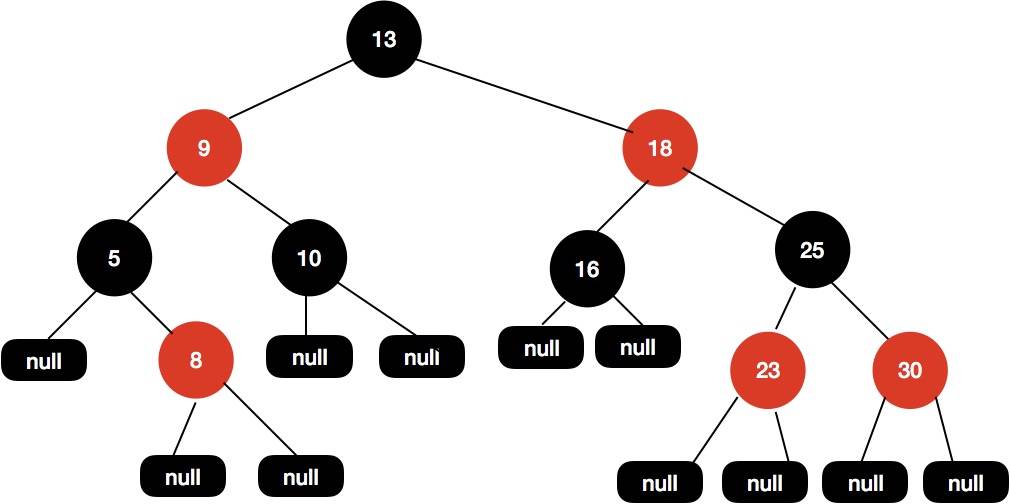
红黑树与AVL树不同,严格来说不是平衡二叉树没要求每个节点的左右节点的高度差值不超过1,红黑树是保持”黑平衡”的二叉树。